In my previous post we handled timeouts with requests. This post deals with making it easier to react to the errors using the built-in retry features.
In this context let’s limit the retry-requiring cases in two categories:
- Cases that timed out (no response from the server)
- Cases that returned a transient error from the server
Let’s look at the second case first, and go to a demo right away:
>>> import requests
>>> from requests.adapters import HTTPAdapter
>>> import urllib3
>>> print(urllib3.__version__)
1.26.9
>>> from urllib3 import Retry
>>> session = requests.Session()
>>> adapter = HTTPAdapter(max_retries=Retry(total=4, backoff_factor=1, allowed_methods=None, status_forcelist=[429, 500, 502, 503, 504]))
>>> session.mount("http://", adapter)
>>> session.mount("https://", adapter)
>>> start_time = time.monotonic()
>>> try:
... r = session.get("http://httpbin.org/status/503")
... except Exception as e:
... print(type(e))
... print(e)
...
<class 'requests.exceptions.RetryError'>
HTTPConnectionPool(host='httpbin.org', port=80): Max retries exceeded with url: /status/503 (Caused by ResponseError('too many 503 error responses'))
>>> stop_time = time.monotonic()
>>> print(round(stop_time-start_time, 2), "seconds")
14.77 seconds
>>>
Captured packets, filtered by HTTP protocol only:
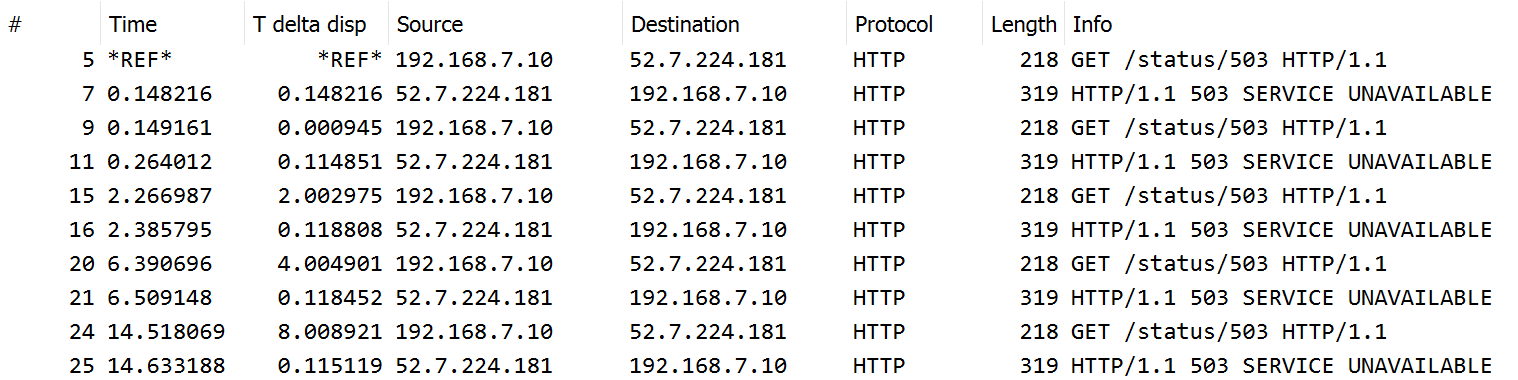
httpbin.org is a service that lets us test against various server outputs. In this case we requested URI /status/503 and it always responded with an HTTP 503 (Service Unavailable) status code.
What happened here is that we used a urllib3.Retry class instance to define the retry strategy with the following parameters:
- four retries (in addition to the original request)
- backoff factor of 1 for the retry delay (the formula for the delay is
{backoff factor} * (2 ** ({retry number} - 1)), except that the first retry is always immediate) - retry with all HTTP methods (
None= a falsy value = retry on any verb, you can also use a list of uppercase HTTP verbs if desired to limit the retries to specific verbs) - retry with HTTP status codes 429, 500, 502, 503 and 504 only
It resulted in five requests in total:
- the original request
- since a 503 was returned, first retry was sent after 0 seconds (immediate retry)
- again 503 was returned, second retry was sent after 2 seconds: 1 * (2 ** (2-1)) = 2
- again 503 was returned, third retry was sent after 4 seconds: 1 * (2 ** (3-1)) = 4
- again 503 was returned, fourth retry was sent after 8 seconds: 1 * (2 ** (4-1)) = 8
Thus it took a total of 2+4+8 = 14 seconds (plus latencies) to raise a requests.RetryError.
Practical use case for this is a NetBox server behind a reverse proxy or an external load balancer for TLS offloading. While the NetBox server is restarting the load balancer might return 5xx status codes to the API clients. If the API client used 5 retries with backoff_factor of 1.5, it would result in 6 attempts in total of about 45 seconds (retry delays of 0+3+6+12+24=45 seconds), which is usually plenty of time for a NetBox server to get up and responding again during a server restart.
Note: When using retries with specific HTTP verbs and status codes you need to be careful about cases when you for example sent a POST request and the server actually modified the application data in addition to returning a retry-eligible status code, causing your client to resend the same (already handled) data.
Now that we can deal with transient server-side errors let’s try adding the timeout handling with it (the first case described in the beginning of this post), using the previously defined TimeoutHTTPAdapter:
>>> session = requests.Session()
>>> adapter = TimeoutHTTPAdapter(timeout=(3, 60), max_retries=Retry(total=5, backoff_factor=1.5, allowed_methods=False, status_forcelist=[429, 500, 502, 503, 504]))
>>> session.mount("http://", adapter)
>>> session.mount("https://", adapter)
>>> start_time = time.monotonic()
>>> try:
... r = session.get("http://192.168.8.1/")
... except Exception as e:
... print(type(e))
... print(e)
...
<class 'requests.exceptions.ConnectTimeout'>
HTTPConnectionPool(host='192.168.8.1', port=80): Max retries exceeded with url: / (Caused by ConnectTimeoutError(<urllib3.connection.HTTPConnection object at 0x7f2bd65a4a60>, 'Connection to 192.168.8.1 timed out. (connect timeout=3)'))
>>> stop_time = time.monotonic()
>>> print(round(stop_time-start_time, 2), "seconds")
63.06 seconds
>>>
This time we used a connect timeout of 3 seconds and read timeout of 60 seconds (the timeout tuple of (3, 60)). The read timeout was never applied in this example because the connection didn’t succeed at all so there was no data to be read.
Captured packets:
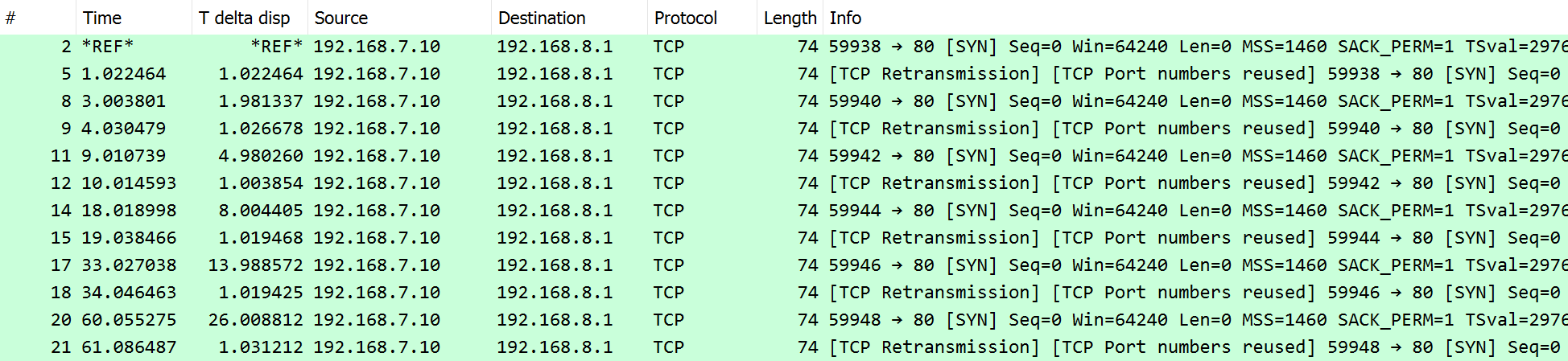
When looking at the packets the delays are not immediately apparent. Let’s look closer per packet (by the packet number in the first column):
- #2 is the initial request, starting the 3-second connect timer
- #5 is a TCP-level retry for #2 (by the host TCP stack, not from the application)
- At #8 the 3-second connect timeout was expired and the application-level
Retrylogic kicked in with the immediate first retry- #9 is a TCP-level retry for #8
- #11 is our second application-level retry (3 seconds after the 3-second timeout = total 6 seconds after #8)
- #12 is again a TCP-level retry (for #11)
- #14 is our third application-level retry (6 seconds after the 3-second timeout = total 9 seconds after #11)
- #15 is again a TCP-level retry (for #14)
- #17 is our fourth application-level retry (12 seconds after the 3-second timeout = total 15 seconds after #14)
- #18 is again a TCP-level retry (for #17)
- #20 is our fifth application-level retry (24 seconds after the 3-second timeout = total 27 seconds after #17)
- #21 is again a TCP-level retry (for #20), while waiting for the final 3-second connect timeout to elapse
- the
requests.ConnectTimeoutexception was raised after the 3-second timeout after #20 = at 63 seconds in total.
The TCP retries will happen (on this host) after 1, 2, 4 and 8 (and so on) seconds as shown earlier in the timeout post, but only the first one of those gets triggered automatically before the application closed the socket when our own 3-second connect timeout was reached.
So this was about the connect timeout, but what if the same Retry configuration was used when a transient server error was encountered? I ran to same setup again with the httpbin.org service and it resulted in ~45 seconds of delay before requests.RetryError and the following HTTP requests and responses:
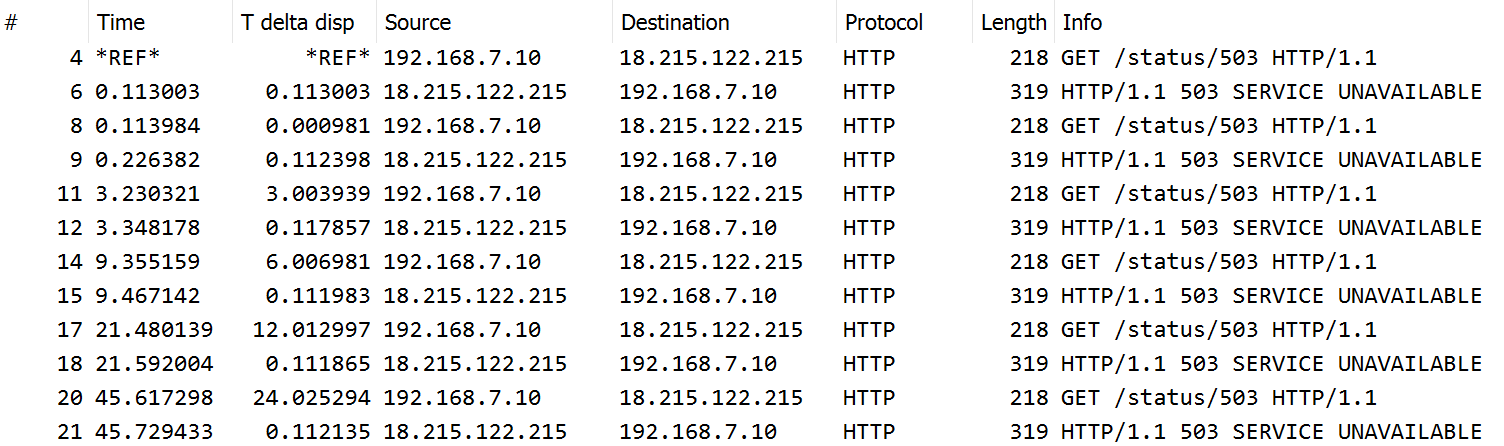
This is again following the earlier pattern, the retries resulted after 0, 3, 6, 12 and 24 seconds, for the total of ~45 seconds. Note that no timeouts were reached because each request resulted with a timely response.
Conclusion
Instead of creating your own application-level looping and control structures for dealing with timeouts and retries you can use a custom requests.adapters.HTTPAdapter (for handling timeouts) and urllib3.Retry (for handling retries).
This article helps me a lot thank you very much ~~~
How did you capture packets ? Is there a command line for mac OS that I can run parallely to verify this behavior of retries and bakcoff?
I don’t use macOS but search for “tcpdump macos” for more information. Command would likely be something like “sudo tcpdump port 80 -w capturefile.pcap -v”