The switches in Ethernet networks learn all connected hosts’ link-layer addresses (layer 2 or MAC (Media Access Control) addresses) dynamically when the hosts communicate in the network and the switches see the traffic. Based on that information the switches are then able to forward frames optimally without flooding.
When you disconnect a physical host from the network and reconnect it in another port in the same network, the switches again learn the new location of that MAC address that is shown in the traffic. Unplugging and then replugging the cable also causes an event in the operating system, and it usually causes some traffic to be sent by the OS or the application stack as well, so MAC learning happens very quickly when the cable is connected again.
But what happens when a virtual machine is live-migrated from a node to another? There is no cable that is disconnected and reconnected (that’s kind of the idea of live migration), and thus the OS or application is not necessarily even aware that something happened, and maybe the VM is not sending anything at that time.
So how does the switched network know that a VM has moved? Let’s find out.
I have a Proxmox Virtual Environment (PVE) cluster with three nodes here. I will move one Windows and one Linux VM from a node to another and see what happens in the network.
Moving a Windows VM
In the first test I’m using a plain Windows Server 2022 VM (IP address 192.168.7.110, MAC address bc:24:11:d4:e9:b9) with no specific agents or drivers installed, meaning that there is no PVE/QEMU/KVM-specific software that would assist in anything related to the migration within the cluster (you don’t think Microsoft would include such agents in its operating systems by default, do you?). The VM is configured with LSI 53C895A SCSI controller and Intel E1000E NIC. The VM disk is stored on shared NFS storage, so we don’t have to move the VM disk, just the VM data in RAM.
There is a ping running with one-second interval from an external host (192.168.7.105) to see how the traffic to the VM is working.
I’m running tcpdump on both the source and destination PVE nodes, capturing the traffic on the node interface that is connected to the physical switch.
I’ll then initiate the VM migration in the PVE cluster. Here is what is shown in the packet captures:
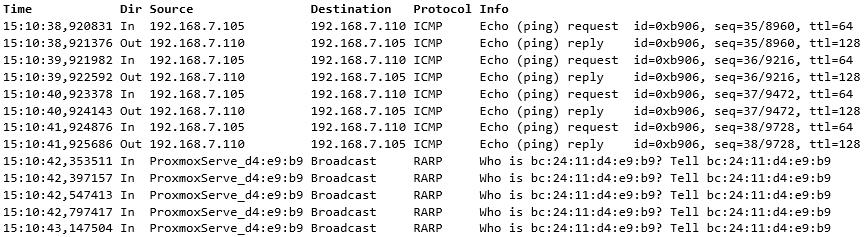
On the source node:
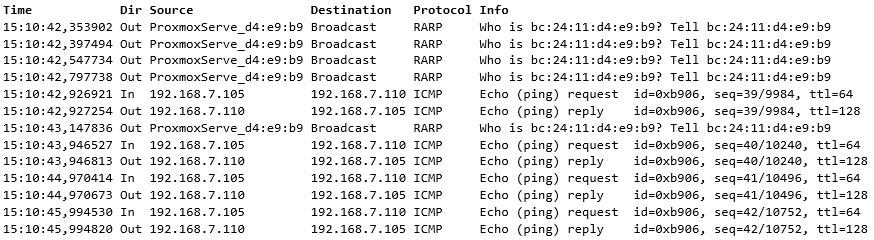
On the destination node:
(I also captured the traffic inside the Windows VM, but there were only the ping packets, you have to take my word for it, I didn’t save the capture file on that.)
Let’s see: On the source node, first there are the continuous pings that are used for testing the connectivity. But then there are a bunch of incoming “RARP” packets. They are Reverse ARP (Reverse Address Resolution Protocol) packets.
RARP is nowadays mostly used in just these situations: to inform the surrounding network infrastructure about MAC address moves in the link layer. The destination PVE node in the virtualization platform sent the RARP packets. The source MAC address of a RARP packet is set to the MAC address of the moved VM, and the switches will learn the new location of that VM instantly.
Side note: Capturing the RARP packets with tcpdump requires using “rarp” filter, “arp” does not catch them.
Right after the RARP packets the pings continue on the destination node, so the MAC move was successful.
The overall result is that no pings were lost because the MAC move (and the RARP packets) happened during the gap of the ping packets.
For the record, this is how the PVE cluster itself logged the VM migration:
15:10:14 starting migration of VM 138 to node 'pve2' (192.168.99.12)
15:10:14 starting VM 138 on remote node 'pve2'
15:10:17 start remote tunnel
15:10:18 ssh tunnel ver 1
15:10:18 starting online/live migration on unix:/run/qemu-server/138.migrate
15:10:18 set migration capabilities
15:10:18 migration speed limit: 80.0 MiB/s
15:10:18 migration downtime limit: 100 ms
15:10:18 migration cachesize: 256.0 MiB
15:10:18 set migration parameters
15:10:18 start migrate command to unix:/run/qemu-server/138.migrate
15:10:19 migration active, transferred 75.5 MiB of 2.0 GiB VM-state, 86.1 MiB/s
15:10:20 migration active, transferred 156.2 MiB of 2.0 GiB VM-state, 82.6 MiB/s
15:10:21 migration active, transferred 236.3 MiB of 2.0 GiB VM-state, 82.2 MiB/s
15:10:22 migration active, transferred 317.0 MiB of 2.0 GiB VM-state, 84.3 MiB/s
...
15:10:39 migration active, transferred 1.6 GiB of 2.0 GiB VM-state, 92.3 MiB/s
15:10:40 migration active, transferred 1.7 GiB of 2.0 GiB VM-state, 80.7 MiB/s
15:10:42 average migration speed: 86.2 MiB/s - downtime 133 ms
15:10:42 migration status: completed
15:10:45 migration finished successfully (duration 00:00:31)
TASK OK
It claims “downtime 133 ms” just at 15:10:42 when the RARP packets were sent as well, so the timestamps match. Migration speed has been manually limited to 80 MB/s on this PVE cluster of 1 Gbps links only, to protect data traffic during migrations.
To conclude this test, all went fine, and RARP was used to get the switches learn the new MAC address location quickly.
Moving a Linux VM
In the second test I’m using a Linux VM (IP address 192.168.7.66, MAC address bc:24:11:ac:e2:75). This Debian 12 host has Debian-packaged qemu-guest-agent installed, version 7.2+dfsg-7+deb12u6. That’s an agent that brings more integration between the hypervisor and the running VM. Linux kernels since ancient times include the VirtIO drivers, so I’m using “VirtIO SCSI single” for the SCSI driver and “VirtIO (paravirtualized)” NIC on the VM.
There is again ping running from 192.168.7.105, and traffic is additionally captured on the VM itself.
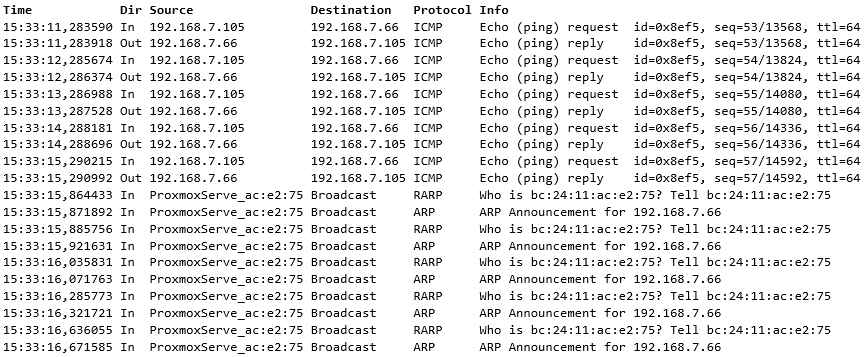
On the source node:
On the destination node:
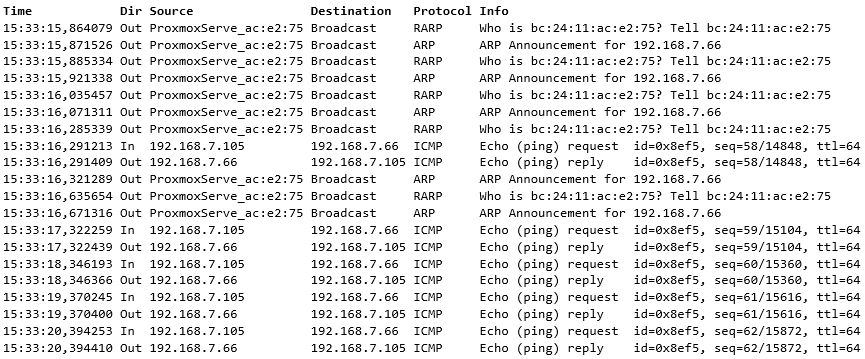
Again, starting from the source node, we first see the continuous pings with one-second intervals, and then we see the RARP packets when the VM move is being finalized.
But we also see ARP Announcements that seem to be coming from the destination node, just like the RARP packets.
Let’s look at the capture on the Linux VM itself:
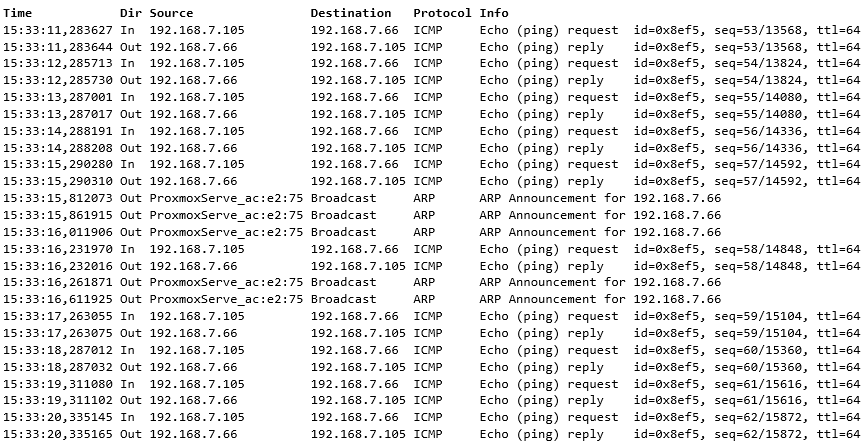
This is something new to me: the ARP Announcements are generated on the VM itself.
I have to assume they are coming from the QEMU guest agent as we didn’t see them in the Windows case. At the time of posting this I haven’t found any direct references for this behavior.
For the packet comparison, here is a Reverse ARP packet, as shown in Wireshark:
Ethernet II, Src: ProxmoxServe_ac:e2:75 (bc:24:11:ac:e2:75), Dst: Broadcast (ff:ff:ff:ff:ff:ff)
Address Resolution Protocol (reverse request)
Hardware type: Ethernet (1)
Protocol type: IPv4 (0x0800)
Hardware size: 6
Protocol size: 4
Opcode: reverse request (3)
Sender MAC address: ProxmoxServe_ac:e2:75 (bc:24:11:ac:e2:75)
Sender IP address: 0.0.0.0
Target MAC address: ProxmoxServe_ac:e2:75 (bc:24:11:ac:e2:75)
Target IP address: 0.0.0.0
And here is an ARP Announcement (or Gratuitous ARP (GARP) as it is also called):
Ethernet II, Src: ProxmoxServe_ac:e2:75 (bc:24:11:ac:e2:75), Dst: Broadcast (ff:ff:ff:ff:ff:ff)
Address Resolution Protocol (ARP Announcement)
Hardware type: Ethernet (1)
Protocol type: IPv4 (0x0800)
Hardware size: 6
Protocol size: 4
Opcode: request (1)
[Is gratuitous: True]
[Is announcement: True]
Sender MAC address: ProxmoxServe_ac:e2:75 (bc:24:11:ac:e2:75)
Sender IP address: 192.168.7.66
Target MAC address: 00:00:00_00:00:00 (00:00:00:00:00:00)
Target IP address: 192.168.7.66
They contain a bit different information, but they are equal for the purposes of MAC move since they both have the VM MAC address as the source address and they are using the broadcast destination address, ensuring that the message is flooded throughout the whole L2 domain and enabling the switches to learn the new location of the MAC address.
In the samples above, the RARP and GARP message intervals are about 20-50 ms, 150 ms, 250 ms and 350 ms between subsequent messages, ensuring that all necessary components of the network get the information.
The GARP packets also contain the IPv4 address of the VM, but it does not matter in this case as the VM IP address did not change, and thus the adjacent devices’ ARP tables don’t need to be updated in the case of MAC address move.
Here is also the PVE cluster log about the VM migration:
15:33:06 starting migration of VM 107 to node 'pve2' (192.168.99.12)
15:33:06 starting VM 107 on remote node 'pve2'
15:33:08 start remote tunnel
15:33:09 ssh tunnel ver 1
15:33:09 starting online/live migration on unix:/run/qemu-server/107.migrate
15:33:09 set migration capabilities
15:33:09 migration speed limit: 80.0 MiB/s
15:33:09 migration downtime limit: 100 ms
15:33:09 migration cachesize: 128.0 MiB
15:33:09 set migration parameters
15:33:09 start migrate command to unix:/run/qemu-server/107.migrate
15:33:10 migration active, transferred 80.7 MiB of 1.0 GiB VM-state, 90.2 MiB/s
15:33:11 migration active, transferred 162.8 MiB of 1.0 GiB VM-state, 101.8 MiB/s
15:33:12 migration active, transferred 243.0 MiB of 1.0 GiB VM-state, 80.3 MiB/s
15:33:13 migration active, transferred 324.2 MiB of 1.0 GiB VM-state, 229.3 MiB/s
15:33:14 migration active, transferred 404.4 MiB of 1.0 GiB VM-state, 80.0 MiB/s
15:33:15 average migration speed: 173.5 MiB/s - downtime 36 ms
15:33:15 migration status: completed
15:33:19 migration finished successfully (duration 00:00:13)
TASK OK
Conclusion
Simply put: The virtualization platforms will help in the VM live migration cases by sending the RARP and/or GARP packets when a VM is moved. The switches can then learn the new location of the VM based according to the source MAC address present in the RARP/GARP packets.