Proxmox Virtual Environment (PVE) has a built-in clustering feature that allows you to access all PVE nodes within the cluster by connecting to any of the nodes, by using a web browser or by connecting to the REST API.
I’m using the out-of-the-box Zabbix template (Proxmox VE by HTTP) to monitor my three-node PVE cluster. I need to select one node as the destination for the monitoring because there is no separate virtual IP address for the cluster. A small problem is that if the monitored node fails or is in maintenance, monitoring won’t work for other nodes or their resources either. Obviously I could monitor all the nodes with Zabbix, but that would cause duplicate data and events as all nodes present all the metrics of the whole PVE cluster.
As mentioned, there is no built-in cluster IP on the PVE cluster, but since PVE nodes are similar to normal Debian servers, Keepalived can be installed on them to provide a virtual IP address to the cluster using VRRP (as I showed in my earlier post about VRRP with Keepalived).
And that’s what I did on my PVE cluster.
Note: This is not supported or recommended by the Proxmox team, so you need to consider yourself if you want to take this road.
Also note that there is an upcoming Proxmox Datacenter Manager application that is currently in the alpha development phase. Over time it may present some official solution for PVE cluster monitoring, provided that you can make the PDM service itself highly available.
Configuring VRRP on the PVE nodes
My PVE nodes are:
- pve1.example.com (192.168.10.101)
- pve2.example.com (192.168.10.102)
- pve3.example.com (192.168.10.103)
They are all running PVE version 8.4.1 that is the latest at the time of writing this.
The VRRP configuration is started by installing Keepalived as root user:
apt install keepalived
A new configuration file is needed in /etc/keepalived/keepalived.conf. Here is the configuration on pve1:
global_defs {
script_user zabbix
enable_script_security
}
vrrp_script check_pveproxy {
script "/usr/bin/nc -z 127.0.0.1 8006"
interval 1
weight -10
}
vrrp_instance PVE {
interface vmbr0.10
virtual_router_id 10
virtual_ipaddress {
192.168.10.100/24
}
priority 101
unicast_peer {
192.168.10.102
192.168.10.103
}
track_script {
check_pveproxy
}
}
Let’s see some of the details:
- I’m using my
zabbixuser as an unprivileged user to run the track script (I have Zabbix agent 2 installed sozabbixuser was created automatically earlier). - The track script continuously checks the PVE web GUI/REST API port availability with
netcat, meaning that if the API port is not accessible, VRRP priority is lowered. I could also monitorpreproxy.servicestatus withsystemctl, or do other checks to validate that PVE is running. - Interface
vmbr0.10is my PVE management VLAN on this setup. - I set the priority for this node as 101, and the other nodes as 102 and 103 correspondingly. This is because I happen to want pve3 to usually be the VRRP master in the group, followed by pve2 and pve1.
- This time I’m using unicast VRRP instead of the normal VRRP multicast, so I listed all the other nodes in this configuration.
Almost the same configuration is set to the other nodes as well, with these changes:
- Priority is set as 102 on pve2, and 103 on pve3 (to favor my higher-performance nodes)
- Unicast peer list contains all other nodes, so pve2 lists 192.168.10.101 and 192.168.10.103, and pve3 lists 192.168.10.101 and 192.168.10.102.
After restarting Keepalived with “systemctl restart keepalived” on all three nodes, VRRP is running, with pve3 node as master in the VRRP group.
It can be validated by connecting to the VIP address 192.168.10.100 with SSH or web browser, and/or by using a command like “ip addr show dev vmbr0.10” to see the VIP active on one node.
This was basically it to create a stable VIP address for always reaching one available node in a PVE cluster.
However, there is a caveat: When you check the SSH key or TLS certificate of the active node using the VIP address, it changes every time the VRRP master is changed.
In my setup I use DNS names and trusted TLS certificates to validate the management connections to pve1.example.com, pve2.example.com and pve3.example.com. If I connect to the VIP address 192.168.10.100 instead, I will get certificate errors. The certificate errors can be prevented by creating a new DNS name for the cluster VIP address and adding the cluster DNS name to the TLS certificates.
Configuring TLS certificates for the cluster name
I’ll configure my DNS with pvecluster.example.com = 192.168.10.100. This lets the API clients and web browsers to connect to the VIP address using the DNS name.
In the web GUI, on each PVE node, there is the System – Certificates configuration. In the ACME section I already have the local node name in the Domain list. I now add the cluster DNS name in the list as well:
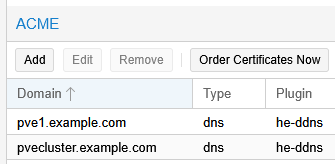
Note: The Type and Plugin values are of course dependent on your own ACME setup. I’m using DNS validation with my DDNS API plugin for Hurricane Electric DNS. See the Proxmox VE Administration Guide to set up your certificate configurations if needed.
The same PVE cluster DNS name pvecluster.example.com is added to the list on each PVE node. The node names (pve1.example.com, pve2.example.com and pve3.example.com) are still node-specific and different on each node.
After ordering new certificates successfully for all nodes, all the nodes now have the pvecluster.example.com name in the certificates in addition to the node-specific names.
Now the URL https://pvecluster.example.com:8006 can be used for connecting to the cluster without TLS certificate errors.
A small cosmetic issue is that the browser title bar still shows the node name of the active VRRP node and not the cluster name. That’s because the PVE web GUI is not specifically configured to detect the name used in the URL. This is understandable because this cluster VIP and DNS name is totally outside of the supported PVE configuration.
Closing thoughts
This cluster VIP setup works great in my own lab PVE cluster, for my own needs. If the cluster is larger, like 5+ nodes, maybe it would be enough to set up VRRP only between a few nodes, like three or four max, to have enough VRRP redundancy for cluster management and monitoring.
A few years ago I wrote a post about Zabbix clustering with Corosync and Pacemaker, so maybe Pacemaker could be added in the Corosync setup of PVE, to create the VIP that way? I didn’t even try it as the Corosync setup is crucial for PVE cluster internals, so I didn’t want to touch it too much.
If you try to do anything mentioned above in your own PVE cluster and it breaks, well, you can keep all the pieces.