In my earlier posts I have shown the Microsoft Windows DHCP server failover configuration behavior where the servers independently decide who will answer to which DHCP clients, using a hashing algorithm based on client hardware address field (usually containing MAC address) in the DHCP packets.
In this post I will show how the failover system works when the DHCP client doesn’t get all the responses from the DHCP servers.
Let’s recap how the DHCP failover setup works in a simple case with one DHCP relay and two DHCP servers, for the offering phase:
- DHCP client broadcasts a
DHCPDISCOVERmessage - The subnet-connected DHCP relay unicasts the message to both configured DHCP servers
- DHCP servers get the message, and one DHCP server responds to the client with
DHCPOFFER, sending the message to the DHCP relay - DHCP relay sends the
DHCPOFFERmessage to the DHCP client.
It is quite evident that in this chain of events something can certainly go wrong, causing the DHCP client to not get any response. For example, the DHCP relay may be misconfigured, sending the DHCP messages to invalid IP addresses, or not sending them anywhere at all. Or, since DHCP is using UDP packets, they could be dropped somewhere along the path due to network congestion.
When the DHCP client doesn’t get a response (DHCPOFFER in this example), it will most probably try again.
In DHCP message there is a field named secs. In RFC 2131 the field description says:
Filled in by client, seconds elapsed since client began address acquisition or renewal process.
RFC 2131, section 2
Sounds simple, right? If the client doesn’t get response to the queries, it will try again later, increasing the secs field value accordingly. Normally the client should get response right away, so there is no need to retry or have any other value than zero in the secs field.
Now, do you remember how the DHCP servers decide independently of each other who responds to which clients and who should just ignore the message?
There is a catch: When the DHCP server gets a DHCP message where the secs field has a non-zero value, it can think that the client has not received any response to its query. Based on that information the DHCP server that didn’t originally want to respond at all (because the other server should handle the client) may want to adjust its own behavior and start responding.
As mentioned above, one example of a failure scenario is misconfigured DHCP relay where not all DHCP servers are properly added in the list of DHCP servers where the packets should be forwarded. This can lead to situation where only one DHCP server gets the client’s DHCPDISCOVER message, but the server decides to not respond to it because the hashing algorithm says to ignore the client (again, because the other DHCP server in the failover setup is supposed to serve the client).
When same client keeps sending the DHCPDISCOVER again and again, increasing the secs field, the DHCP server can realize that no other server is responding, and it can start responding instead.
Side note: Since the DHCP servers in failover setup are communicating directly with each other with a TCP-based protocol, they know if their peer is serving DHCP or not. If the peer is not actually running at all, the server can assume responsibility of all DHCP clients immediately, without any delays or using the secs field information.
Anyway, let’s see how this secs thing works.
I’ll have a “DHCP client” built using Scapy, the interactive packet manipulation library for Python. It will send ten DHCPDISCOVER messages in one-second intervals, with secs field value starting from zero and increasing it by one every next message. It won’t send any DHCPREQUEST messages though, simulating the situation where the DHCP client keeps on trying when it doesn’t receive any DHCPOFFER. The DHCP relay is configured correctly, so it will send the DHCPDISCOVER messages to both of my Windows Server 2022 DHCP servers, 10.0.41.30 and 10.0.41.31. I’ll capture all the DHCP messages with tcpdump on the client. You can download the capture file here: dhcp-seconds.pcap (github.com)
This is how it looks like on the capture:
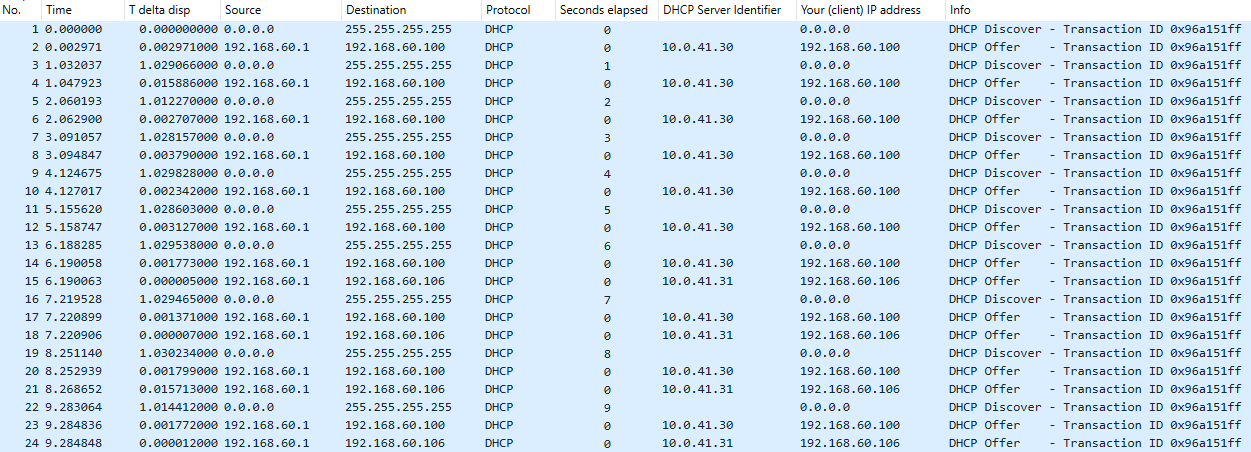
Here we can see that for the first six DHCPDISCOVER messages (with secs values of 0 to 5) only the 10.0.41.30 server responded with DHCPOFFER, but for the last four packets both servers responded.
So, it looks like the secs value threshold is 6 for the second server to conclude that there is something wrong and it should start responding as well.
I repeated the tests various ways and kept receiving the same results: regardless of the packet interval it was always the secs value that determined the server behavior, and it was a value of 6 or higher that triggered it.
However, in real-life DHCP servers I have seen that already a value of 3 has triggered the behavior. Go figure, I don’t know of any official documentation that would define the actual threshold value. Let me know if you have any pointers.
Note that in this example the DHCP relay was correctly configured and the DHCP client received all the responses correctly, but the client itself decided to not react to the responses. But the servers cannot know the actual reason for the situation, so eventually the second server decided to start responding as well, in order to get an offer to the client.
Also note that both DHCP servers offered a different IP address to the client:
- 10.0.41.30 offered 192.168.60.100
- 10.0.41.31 offered 192.168.60.106
That’s normal because in the failover setup the servers have internally split the available IP pool between each other. The split happens automatically, and when the server has finally acknowledged a DHCPREQUEST message from a client (if it ever proceeds that far), it will tell the other server about the new lease, so they will both eventually have the same information about the leases in use.
From the DHCP client point of view it is not a problem if it ever receives different offers from different servers, as it can then select one of the offers as it likes.
Again, in this example above the situation was caused by the DHCP client itself, artificially. But, as mentioned, similar cases will occur when the DHCP relay is missing one of the DHCP servers from the configuration: statistically 50% of the DHCP clients won’t get any DHCPOFFER for their first DHCPDISCOVER (because the “correct” DHCP server never gets the message!), but eventually, after a few retries, DHCP “starts working” for those clients as well.
By inspecting the actual DHCP packets you should be able to recognize this kind of misconfiguration.
Thanks for this great analysis! I have seen some cases where the DHCP process is either instant or it takes 7 seconds. Today I learned that ISC DHCP failover works in a similar way:
https://www.ipamworldwide.com/ipam/dhcp-loadbal.html
“The load balance max seconds parameter defines a threshold value enabling a server to provide a lease to a client that normally would be served by the other server. The number of seconds defined in this parameter is compared against the Secs parameter in the DHCP message header which is populated by the DHCP client as an indication of the number of seconds that the client has been attempting to contact a DHCP server. “