It’s not rare that as a technical worker you get some data in CSV format (comma-separated values), and the data has to be read and interpreted some way. MS Excel is the default tool for some to handle those cases, but I’m one of those that never got used to using Excel in external data processing. Python is one way to process the data for further actions.
Spoiler: Do not get into string-parsing the CSV lines and columns yourself.
Here is an example of CSV file processing using just Python standard library. The example data is from opendata.fi (the Helsinki and Espoo city bike stations, download link for the data can be found here). Let’s see how the data looks like in my editor (Visual Studio Code):
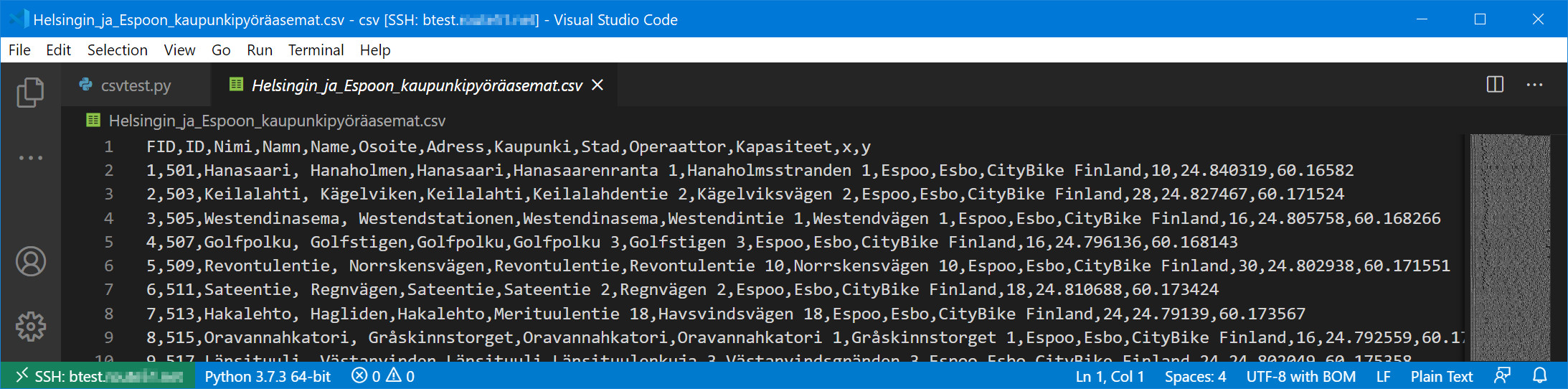
This looks like a genuine CSV (= comma-separated), so we should be good to go. Let’s build our first attempt to parse the data with csvtest.py:
import argparse
import csv
parser = argparse.ArgumentParser()
parser.add_argument("inputfile")
args = parser.parse_args()
with open(args.inputfile) as f:
reader = csv.DictReader(f)
for cols in reader:
print("{} = FID {}".format(cols["Name"], cols["FID"]))
We use the argparse module to get the input file name from the command line as shown below. The reader object is an iterator that is used in a for loop to get all the columns line by line, so this should print all the “Name” and “FID” fields of the file. Let’s run it:
markku@btest:~/csvdemo$ python3 csvtest.py Helsingin_ja_Espoon_kaupunkipyöräasemat.csv
Traceback (most recent call last):
File "csvtest.py", line 10, in <module>
print("{} = FID {}".format(cols["Name"], cols["FID"]))
KeyError: 'FID'
markku@btest:~/csvdemo$What’s wrong, field “FID” is not found? But apparently “Name” is found as it was parsed earlier and no complaints were shown for it.
Let’s try with raw data to find out what’s going on, by printing the whole cols object for all the lines:
import argparse
import csv
parser = argparse.ArgumentParser()
parser.add_argument("inputfile")
args = parser.parse_args()
with open(args.inputfile) as f:
reader = csv.DictReader(f)
for cols in reader:
print(cols)
It prints us a dictionary for each line, consisting of “column name, value” tuples:
markku@btest:~/csvdemo$ python3 csvtest.py Helsingin_ja_Espoon_kaupunkipyöräasemat.csv
OrderedDict([('\ufeffFID', '1'), ('ID', '501'), ('Nimi', 'Hanasaari'), ('Namn', ' Hanaholmen'), ('Name', 'Hanasaari'), ('Osoite', 'Hanasaarenranta 1'), ('Adress', 'Hanaholmsstranden 1'), ('Kaupunki', 'Espoo'), ('Stad', 'Esbo'), ('Operaattor', 'CityBike Finland'), ('Kapasiteet', '10'), ('x', '24.840319'), ('y', '60.16582')])
OrderedDict([('\ufeffFID', '2'), ('ID', '503'), ('Nimi', 'Keilalahti'), ('Namn', ' Kägelviken'), ('Name', 'Keilalahti'), ('Osoite', 'Keilalahdentie 2'), ('Adress', 'Kägelviksvägen 2'), ('Kaupunki', 'Espoo'), ('Stad', 'Esbo'), ('Operaattor', 'CityBike Finland'), ('Kapasiteet', '28'), ('x', '24.827467'), ('y', '60.171524')])
...It looks like the first column name is not “FID” but “\ufeffFID”. There’s a catch for us: There seems to be the Unicode byte order mark (BOM) in the beginning of the file. Actually that was also shown in the editor screenshot above, in the lower right corner (“UTF-8 with BOM”). Using BOM may or may not be a feature of your own CSV-generating applications as well so you may need to be aware of it.
For handling the BOM we don’t want to get into parsing the data bytes ourselves, but let’s use the codecs module (again from the standard library, no need to install any additional packages):
import argparse
import codecs
import csv
parser = argparse.ArgumentParser()
parser.add_argument("inputfile")
args = parser.parse_args()
with codecs.open(args.inputfile, encoding="utf-8-sig") as f:
reader = csv.DictReader(f)
for cols in reader:
print("{} = FID {}".format(cols["Name"], cols["FID"]))
Let’s try again:
markku@btest:~/csvdemo$ python3 csvtest.py Helsingin_ja_Espoon_kaupunkipyöräasemat.csv
Hanasaari = FID 1
Keilalahti = FID 2
Westendinasema = FID 3
Golfpolku = FID 4
Revontulentie = FID 5
...Now it’s working nicely: We can reference the fields by the column names (as specified in the first line of the CSV file), not needing to index by numbers.
How about commas in the data? In our example data we happen to have some of those:
...
22,539,"Aalto-yliopisto (M), Tietot"," Aalto-universitetet (M),","Aalto University (M), Tietotie",Tietotie 4,Datavägen 4,Espoo,Esbo,CityBike Finland,20,24.820099,60.184987
23,541,"Aalto-yliopisto (M), Korkea"," Aalto-universitetet (M),","Aalto University (M), Korkeakoulua",Otaniementie 10,Otnäsvägen 10,Espoo,Esbo,CityBike Finland,42,24.826671,60.184312
24,543,Otaranta, Oststranden,Otaranta,Otaranta 6,Otstranden 6,Espoo,Esbo,CityBike Finland,22,24.837133,60.18483
25,545,Sähkömies, Strömkarlen,Sähkömies,Otakaari 3,Otsvängen 3,Espoo,Esbo,CityBike Finland,12,24.829985,60.188499
...In the FIDs 22 and 23 there are commas in the name columns, and the data is quoted in those columns to contain the commas in the data, not to be mixed with the commas used for separating the data to the columns.
You can see the output of our sample code for those lines:
markku@btest:~/csvdemo$ python3 csvtest.py Helsingin_ja_Espoon_kaupunkipyöräasemat.csv | grep Aalto
Aalto University (M), Tietotie = FID 22
Aalto University (M), Korkeakoulua = FID 23
markku@btest:~/csvdemo$Nice! The csv library automatically handled the column quoting for us.
How do we handle other column separators than comma? A semicolon (“;”) is a common one. Let’s try with this input data semitest.csv:
Name;Characters
Item1;abcd
Item2;",;""."There is also a double-quote test there. Here is our new code, semitest.py:
import argparse
import codecs
import csv
parser = argparse.ArgumentParser()
parser.add_argument("inputfile")
args = parser.parse_args()
with codecs.open(args.inputfile, encoding="utf-8-sig") as f:
reader = csv.DictReader(f, delimiter=";")
for cols in reader:
print("Name {} = characters {}".format(cols["Name"], cols["Characters"]))
The differences here are the delimiter argument to DictReader and of course the column names that are printed. Let’s try it:
markku@btest:~/csvdemo$ python3 semitest.py semitest.csv
Name Item1 = characters abcd
Name Item2 = characters ,;".
markku@btest:~/csvdemo$Seems to work fine: semicolon is used correctly as the separator, and double-quote character works inside the double quotes when entered twice in the data. Also, even though maybe not visible exactly, our semitest.csv input file did not have the BOM but our “BOM code” with codecs still worked just fine.
What if your CSV file does not have the column header line? Then you don’t use csv.DictReader but csv.reader, and you need to use column indexing (starting from 0) to get the fields you need. Sample data (justdata.csv) and the code (csvtest2.py) to handle it:
Item1;some data
Item2;some different dataimport argparse
import codecs
import csv
parser = argparse.ArgumentParser()
parser.add_argument("inputfile")
args = parser.parse_args()
with codecs.open(args.inputfile, encoding="utf-8-sig") as f:
reader = csv.reader(f, delimiter=";")
for cols in reader:
print("Item = {}, value = {}".format(cols[0], cols[1]))
Here is the output:
markku@btest:~/csvdemo$ python3 csvtest2.py justdata.csv
Item = Item1, value = some data
Item = Item2, value = some different data
markku@btest:~/csvdemo$One more thing. What if your quoted input data contains linefeeds, like this (multilinedata.csv and csvtest3.py):
Item1,One line data
Item2,"Data
in
four
lines"
Item3,"Back to ""normal"""import argparse
import codecs
import csv
parser = argparse.ArgumentParser()
parser.add_argument("inputfile")
args = parser.parse_args()
with codecs.open(args.inputfile, encoding="utf-8-sig") as f:
reader = csv.reader(f)
for cols in reader:
print("Item = {}, value = '{}'".format(cols[0], cols[1]))
Basically we don’t have any special handling in our code, just using the columns by indexing as in the previous example, and this happens (note the single-quotes in the print() statement to make it clear where each value starts and ends):
markku@btest:~/csvdemo$ python3 csvtest3.py multilinedata.csv
Item = Item1, value = 'One line data'
Item = Item2, value = 'Data
in
four
lines'
Item = Item3, value = 'Back to "normal"'
markku@btest:~/csvdemo$What can I say, it just works. (Btw, if you are sure that the linefeeds should not be there in the input data you can eliminate them in the output by replacing cols[1] in the example with cols[1].replace("\n", " ").)
The key takeaway from this post:
Even though creating and testing code by yourself for common operations (like CSV parsing) can be an educating experience, when the end goal is something else don’t try to reinvent the wheel straight away but make use of the existing libraries.
References to Python documentation: